Linux Maximus: The RAW Facts on File Systems
By Bert Scalzo, PhD
"There is nothing as deceptive as an obvious fact." - Arthur Conan Doyle
Welcome to the second article on maximizing the performance of Linux systems. The goal of these articles is to offer some relatively simple yet highly effective tuning ideas. Moreover, all such suggestions must adhere to the "KISS" ideal. All the tuning techniques must be both easily implemented and easily measured. Our ideal technique must fit the model of: perform a baseline benchmark, implement the proposed change, perform a comparative benchmark, followed by a big smile.
Last time, we obtained over a 1000% improvement in database load times and a 50% improvement in the number of transactions per second. While some of the techniques from last time were overly basic in nature (i.e. DBA 101 and Linux System Admin 101), it was necessary to start at the beginning so as not to miss any low hanging fruits along the way. Now it's time to tackle slightly more interesting and challenging tuning concepts.
Today we'll examine Linux multi-devices (RAID), logical volume managers (LVM), cooked versus raw file systems, and regular versus journalized file systems. I guarantee that some of the enclosed benchmark results and conclusions will surprise you.
Spread the Load
Sometimes the best the place to start tuning is simply to apply some of the age-old adages we've heard hundreds, if not thousands of times:
- More is better
- The more the merrier
- There's strength in numbers
- Two heads are better than one
- Four of a kind beats all but a straight or royal flush
Nowhere do these principles apply more than with disk drives.
Today's PC's and servers have CPU's that run as fast as two gigahertz, memory that refreshes in nanoseconds, and buses that transfer data in excess of 266 MB / second. But although disk prices have plummeted and disk sizes have skyrocketed, disk I/O remains public enemy number one. Disks are still just mechanical devices that spin from 5400 to 15000 RPM, with data transfer rates of only 20-160 MB / second. As such, disk drives continue to be most computers Achilles' heal - at nearly 2-8 times slower than the rest of the system's components!
Regardless of whether you're partial to SCSI or IDE for your Linux system, buy lots of disks - they're cheap enough. For IDE drives, I highly recommend 7200 RPM units with at least two megabytes of cache on each drive. Over the past few years, IBM has scored very well in reviews at www.tomshardware.com (read "Fastest IDE Hard Drive Ever: IBM Deskstar 75GXP"). And for SCSI, I would not presume to dispute the legions of Seagate Cheetah fanatics out there (read "We Have a Winner - Seagate's Cheetah X15"). With sustainable minimum data transfer rates of 30+ MB / second, this drive makes minced meat of most real world benchmarks.
For those with an actual budget, of course you'll be buying SAN and NAS disk arrays.
My humble little test machine was a dual PIII-933 with 2 GB RAM, two Symbios SCSI Ultra 2 controllers, and ten SCSI Ultra 2 7200 RPM 18 GB disk drives - with all 10 disks implementing RAID 0 (i.e. striping) for maximum speed. Don't laugh - I recently placed a bid on eBay for an EMC 5500 with 1.5 terabytes. And yes, my Master Card is set up for paperless service and I pay it online to avoid upsetting the wife with my little escapades.
Organize the Herd
OK, so you've bought your gaggle of disk drives - now what?
In the old days, we tried to map out files across controllers, channels and disks. Either I'm getting too old or just too lazy for that approach - RAID is the only way to go now. Notice I didn't say what which level of RAID (i.e. 0, 1, 0+1, 3, 5, 7), just RAID. You'll have to decide for yourself whether you need speed, reliability or both. For my test cases, I stuck with RAID 0 (striping) - as I wanted to get the best possible benchmarks. In real life, I've always done either RAID 5 or 0+1.
Assuming that you don't have SAN or NAS disk arrays that come preconfigured as RAID, you have but three simple choices to implement RAID across Linux disks:
- Hardware - RAID disk controller (often with up to 128 MB cache)
- Software - the md Multi-Device kernel module
- Software - A Logical Volume Manager (LVM)
Now without any intent to alienate or offend the RAID disk controller vendors out there, let me advise that you do not select this option. The Linux RAID device drivers are almost universally listed as tier 3 level of support - essentially meaning you're on your own. A few made it to tier 2 level of support, but these are mostly the more expensive controllers on the market. And if there's one problem we absolutely want to avoid, it's Linux device driver problems. Life's too short for this kind of pain.
So now the big question is do we use the Multi-Device or the Logical Volume Manager?
The Multi-Device has been around since kernel 2.0. Now I don't want to trash this neat little feature, but those of us who gnawed our teeth on other Unix platforms have always used LVM's. The md kernel patch always felt like a kludge to pacify the need for RAID until LVM's for Linux became available. That said, I do use Multi-Devices for my "swap" and "/" file systems - because most Linux installers currently support this option for striping. It's a royal pain in the you know what to try and do this for these two file systems with LVM's - again, just not worth the effort.
So, I 100% recommend a LVM for all your database file systems. Let's look at the major steps how we would set something like this up:
- Create 8E (i.e. LVM) type hard disk drive partitions
- Create physical volumes using the pvcreate command
- Create volume group(s) using the vgcreate command
- Create logical volumes using the lvcreate command
- Create the file systems using the mxfs.xxxx command
- Create a directory to associate with
- Mount the device to the directory
For example, let's assume we add four new 9 GB SCSI disks to our box (which already has four SCSI disks) and that we want to create a single RAID 0 ext2 file system named /data across those drives. The commands would be as follows:
for i in e f g h
do
sfdisk /dev/sd$i << EOF
0,9216,8E
EOF
pvcreate /dev/sd$i
done
vgcreate vg01 /dev/sd[e-h]
lvcreate –i 4 –I 64 –L 36G –n lv01 vgo1
mke2fs /dev/vg01/lv01
mkdir /data
mount /dev/vg01/lv01 /dataFor the other various file systems the mk2efs command would change to:
mke2fs -j(the new ext3 journalized file system)mkreiserfs(the popular Resier journalized file system)mkfs.jfs(tried and true IBM journalized file system)
And for RAW devices, the final three lines above would be replaced by:
mknod /dev/rawctl
mknod /dev/raw1 c 162 $i
raw /dev/raw1 /dev/vg01/lv01Beware Apples and Oranges
One of the biggest problems I see with people implementing databases on Linux is that they almost always rely on one or more of the popular Linux benchmark techniques or programs out there. The trouble is that they are almost universally just basic file system throughput tests. Examples include:
- Bonnie
- Bonnie++
- Mongo
- Dbench
- Postmark
- Iozone
- Iobench
The problem is that these tests and their obtained results generally do not apply in any meaningful fashion to relational database systems and the way they access data files.
For example, I've included the Iozone benchmark results from my test machine. Note the ext2 and IBM-JFS file systems scored first and second in every single category. The ext3 and Resier file systems however appear as big time losers for my test box and these tests. Remember this a little later when we look at traditional database benchmark test results generated by Quest Software's Benchmark Factory. These findings will not hold true.
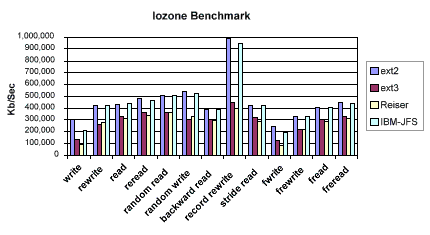
Let's Rumble
OK, we've agreed on lots of disks, RAID and using a LVM - plus we saw that the standard Linux benchmarks are not entirely reliable - but which Linux file system works best for relational databases? Simple enough question, so onto a simple and clear answer.
I wanted to run two well-known and widely accepted database benchmarks:
- AS3AP - a scalable, portable ANSI SQL relational database benchmark. This benchmark provides a comprehensive set of tests for database processing power; has a built-in scalability and portability that tests a broad range of systems; minimizes human effort in implementing and running benchmark tests; and provides a uniform metric straight-forward interpretation of benchmark results.
- TPC-C - an online transaction processing (OLTP) benchmark. This benchmark involves a mix of five concurrent transactions of different types, and completely executes either online or queries for deferred execution. The database is comprised of nine types of tables having a wide range of record and population sizes. This benchmark is measured in transactions per minute.
But of course I don't know the DDL, DML or anything about these tests - other than their names and significance as benchmarks. I also don't want to pay lots of money to join some industry collation in order to have access to these benchmarks' SQL code.
So I used Quest Software's Benchmark Factory (shown below), as it permits me to easily select and run such tests in a matter of minutes. You just pick a database, pick an industry standard test, provide a few options regarding desired database size and concurrent user load, and that's it - really. Benchmark Factory even permits me to run concurrent user loads using many PC's on my network in the case that I do not like having a single PC simulate the load. You're wasting real time and money if you're doing benchmarks by writing code. Benchmark Factory let's me focus on the tuning instead of the benchmark.
And the Winner Is …
First let's look at the AS3AP test results. For database creation, loading and indexing, Figure 1 shows that the EXT3 file system wins hands down - and that RAW devices come in next to last place! How many saw that coming?
Moreover, the extremely popular Reiser file system completely choked on the index builds - taking over 2.6 times the average index creation time. Remember the Iozone benchmark above where Reiser was a winner? So see, file system benchmarks don't apply very well to databases.
For the transactional potion of the benchmark, the results in Table 1 were also surprising. All the file systems had roughly the same performance - except for RAW devices, which ran nearly twice as slow on the average time per transaction!
Based upon the AS3AP benchmark results, one should choose the EXT3 file system (a new and much improved version of EXT2 file system, that also offers journaling).
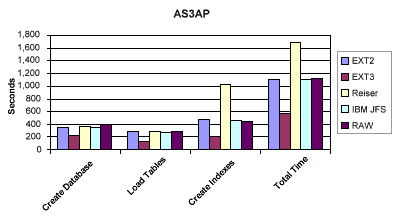
Figure 1
|
AS3AP |
Create |
Load |
Create |
Total |
Trans/ |
Avg |
|---|---|---|---|---|---|---|
|
EXT2 |
345 |
289 |
474 |
1,108 |
254 |
0.205 |
|
EXT3 |
230 |
127 |
221 |
578 |
252 |
0.208 |
|
Reiser |
371 |
291 |
1,029 |
1,691 |
250 |
0.210 |
|
IBM JFS |
350 |
282 |
462 |
1,094 |
253 |
0.207 |
|
RAW |
396 |
290 |
442 |
1,128 |
196 |
0.369 |
Table 1
I personally had a very hard time with RAW devices doing so poorly. So for the TPC-C benchmarks, I added another benchmarking test scenario - giving the RAW device based database twice the memory allocation as its cooked file system counterparts. My thoughts were that maybe the Linux file system buffer cache was skewing my test results.
Well, lightning struck twice in the same spot - because the TPC-C results were nearly the same, relatively speaking, as the AS3AP results (see Figure 2 and Table 2, below)
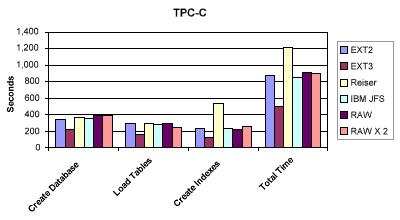
Figure 2
|
TPC-C |
Create |
Load |
Create |
Total |
Trans/ |
Avg |
|---|---|---|---|---|---|---|
|
EXT2 |
348 |
295 |
234 |
877 |
2.758 |
0.016 |
|
EXT3 |
228 |
158 |
122 |
508 |
2.753 |
0.019 |
|
Reiser |
378 |
297 |
537 |
1,212 |
2.757 |
0.028 |
|
IBM JFS |
351 |
277 |
231 |
859 |
2.757 |
0.025 |
|
RAW |
396 |
290 |
225 |
911 |
2.748 |
0.073 |
|
RAW X 2 |
396 |
240 |
263 |
899 |
2.753 |
0.050 |
Once again, the EXT3 file system is the clear winner for database creation, loading and indexing. Once again the Reiser file system came in last - choking on the index builds. And as with the AS3AP benchmark results, all the cooked file systems had roughly the same performance for the transactional portions of the TPC-C benchmark.
Even the RAW device scenario with twice the memory allocation could not compete. In fact, the improvement was so slight as to essentially scare me away from RAW devices on any Linux database project for the foreseeable future.
Based upon the TPC-C benchmark results, one should choose the EXT3 file system.
In closing, it's very reassuring when multiple and different natured, industry standard benchmarks yield similar results. In case you're wondering, I obtained similar results with Benchmark Factory's other half dozen or so database benchmarks. EXT3 it is.