Organize the Herd
OK, so you've bought your gaggle of disk drives - now what?
In the old days, we tried to map out files across controllers, channels and disks. Either I'm getting too old or just too lazy for that approach - RAID is the only way to go now. Notice I didn't say what which level of RAID (i.e. 0, 1, 0+1, 3, 5, 7), just RAID. You'll have to decide for yourself whether you need speed, reliability or both. For my test cases, I stuck with RAID 0 (striping) - as I wanted to get the best possible benchmarks. In real life, I've always done either RAID 5 or 0+1.
Assuming that you don't have SAN or NAS disk arrays that come preconfigured as RAID, you have but three simple choices to implement RAID across Linux disks:
- Hardware - RAID disk controller (often with up to 128 MB cache)
- Software - the md Multi-Device kernel module
- Software - A Logical Volume Manager (LVM)
Now without any intent to alienate or offend the RAID disk controller vendors out there, let me advise that you do not select this option. The Linux RAID device drivers are almost universally listed as tier 3 level of support - essentially meaning you're on your own. A few made it to tier 2 level of support, but these are mostly the more expensive controllers on the market. And if there's one problem we absolutely want to avoid, it's Linux device driver problems. Life's too short for this kind of pain.
So now the big question is do we use the Multi-Device or the Logical Volume Manager?
The Multi-Device has been around since kernel 2.0. Now I don't want to trash this neat little feature, but those of us who gnawed our teeth on other Unix platforms have always used LVM's. The md kernel patch always felt like a kludge to pacify the need for RAID until LVM's for Linux became available. That said, I do use Multi-Devices for my "swap" and "/" file systems - because most Linux installers currently support this option for striping. It's a royal pain in the you know what to try and do this for these two file systems with LVM's - again, just not worth the effort.
So, I 100% recommend a LVM for all your database file systems. Let's look at the major steps how we would set something like this up:
- Create 8E (i.e. LVM) type hard disk drive partitions
- Create physical volumes using the pvcreate command
- Create volume group(s) using the vgcreate command
- Create logical volumes using the lvcreate command
- Create the file systems using the mxfs.xxxx command
- Create a directory to associate with
- Mount the device to the directory
For example, let's assume we add four new 9 GB SCSI disks to our box (which already has four SCSI disks) and that we want to create a single RAID 0 ext2 file system named /data across those drives. The commands would be as follows:
for i in e f g h
do
sfdisk /dev/sd$i << EOF
0,9216,8E
EOF
pvcreate /dev/sd$i
done
vgcreate vg01 /dev/sd[e-h]
lvcreate –i 4 –I 64 –L 36G –n lv01 vgo1
mke2fs /dev/vg01/lv01
mkdir /data
mount /dev/vg01/lv01 /dataFor the other various file systems the mk2efs command would change to:
mke2fs -j(the new ext3 journalized file system)mkreiserfs(the popular Resier journalized file system)mkfs.jfs(tried and true IBM journalized file system)
And for RAW devices, the final three lines above would be replaced by:
mknod /dev/rawctl
mknod /dev/raw1 c 162 $i
raw /dev/raw1 /dev/vg01/lv01Beware Apples and Oranges
One of the biggest problems I see with people implementing databases on Linux is that they almost always rely on one or more of the popular Linux benchmark techniques or programs out there. The trouble is that they are almost universally just basic file system throughput tests. Examples include:
- Bonnie
- Bonnie++
- Mongo
- Dbench
- Postmark
- Iozone
- Iobench
The problem is that these tests and their obtained results generally do not apply in any meaningful fashion to relational database systems and the way they access data files.
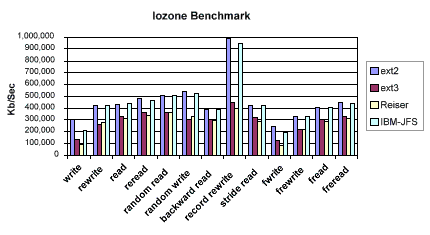
For example, I've included the Iozone benchmark results from my test machine. Note the ext2 and IBM-JFS file systems scored first and second in every single category. The ext3 and Resier file systems however appear as big time losers for my test box and these tests. Remember this a little later when we look at traditional database benchmark test results generated by Quest Software's Benchmark Factory. These findings will not hold true.