Modules and Scoping Rules
- 11.1 What is a module?
- 11.2 A first module
- 11.3 The import statement
- 11.4 The module search path
- 11.5 Private names in modules
- 11.6 Library and third-party modules
- 11.7 Python scoping rules and namespaces
Modules are used to organize larger Python projects. The Python language itself is split into modules to make it more manageable. You don't need to organize your own code into modules, but if you're writing any programs more than a few pages long, or any code that you want to reuse, you should probably do so.
11. 1 What is a module?
A module is a file containing code. A module defines a group of Python functions or other objects. The name of the module is derived from the name of the file.Modules will most often contain Python source code, but they can also be compiled C or C++ object files. Compiled modules and Python source modules are used in the same way.
A module is just a single file containing related functions, constants, and so forth.
As well as grouping related Python objects, modules help avoid name clash problems. For example, you might write a module for your program called MyModule, which defines a function called reverse. In the same program you might also wish to make use of some-body else's module called OtherModule, which also defines a function called reverse, but which does something different from your reverse function. In a language without modules, it would be impossible to use two different reverse functions. In Python, it's trivial-you simply refer to them in your main program as MyModule.reverse and OtherModule.reverse.
Modules are also used to make Python itself more manageable. Most standard Python functions are not built into the core of the language, but instead are provided via specific modules, which the programmer can load as needed.
11. 2 A first module
The best way to learn about modules is probably to make one, so... Create a text file called mymath. py, and in that text file, enter the following Python code (if you are using IDLE, just select New window (figure 11.1) from the File menu and start typing):File mymath. py
""" mymath -our example math module""" pi = 3.14159 def area( r): """ area( r): return the area of a circle with radius r.""" global pi return( pi * r * r)

Save this for now in the directory where your Python executable is. This code merely defines a constant and a function. The .py filename suffix is mandatory for all Python code files. It identifies that file to the Python interpreter as consisting of Python source code. As with functions, we have the option of putting in a document string as the first line of our module. Now start up the Python Shell, and type
>>> pi Traceback (innermost last): File "< stdin>", line 1, in ? NameError: pi >>> area( 2) Traceback (innermost last): File "< stdin>", line 1, in ? NameError: area
In other words, Python doesn't have the constant pi or the function area built in.
Now, type:
>>> import mymath >>> pi Traceback (innermost last): File "<stdin>", line 1, in ? NameError: pi >>> mymath. pi ==> 3.14159 >>> mymath. area(2) ==> 12.56636 >>> mymath.__ doc__ ==> 'mymath -our example math module' >>> mymath. area.__ doc__ ==> 'area( r): return the area of a circle with radius r. '
We've brought in the definitions for pi and area from the mymath. py file, using the import statement (which automatically adds on the .py suffix when it searches for the file defining the module named "mymath"). However, the new definitions aren't directly accessible; typing pi by itself gave an error, and typing area(2) by itself would give an error. Instead, we access pi and area by prepending them with the name of the module that contains them. This guarantees name safety. There may be another module out there which also defines pi (maybe the author of that module thinks that pi is 3.14, or 3.14159265), but that is of no concern. Even if that other module were imported, its version of pi will be accessed by othermodulename. pi, which is different from mymath. pi. This form of access is often referred to as qualification (i. e., the variable pi is being qualified by the module mymath). We may also refer to pi as an attribute of mymath.
Definitions within a module can access other definitions within that module, without prepending the module name. The mymath.area function accesses the mymath.pi constant as just pi.
If we want to, we can also specifically ask for names from a module to be imported in such a manner that we don't have to prepend them with the module name. Type:
>>> from mymath import pi >>> pi ==> 3.14159 >>> area(2) Traceback (innermost last): File "<stdin>", line 1, in ? NameError: area
The name pi is now directly accessible because we specifically requested it using from module import name.
The function area still needs to be called as mymath. area, though, because it was not explicitly imported.
You may want to use the basic interactive mode or IDLE's Python Shell to incrementally test a module as you are creating it. However, if you change your module on disk, retyping the import command will not cause it to load again. You need to use the reload function for this.
>>> import mymath >>> reload(mymath) ==> <module 'mymath'>
When a module is reloaded (or imported for the first time), all of its code is parsed. So a syntax exception will be raised if an error is found. On the other hand, if everything is okay, a .pyc file (i. e. mymath. pyc) containing Python byte code will be created.
Reloading a module does not put you back into exactly the same situation as when you start a new session and import it for the first time. However, the differences will not normally cause you any problems. If interested, you can look up reload in the built-in functions section of the Python Language Reference to find the details.
Of course, modules don't need to be used from the interactive Python shell. They can also be imported into scripts, or other modules for that matter; just enter suitable import statements at the beginning of your program file. Also, internally to Python, the interactive session and a script are considered modules as well.
To summarize:
- A module is a file defining Python objects.
- If the name of the module file is modulename. py, then the Python name of the module itself is modulename.
- A module named modulename can be brought into use with the "import module-name" statement. After this statement is executed, objects defined in the module can be accessed as modulename.objectname.
- Specific names from a module can be brought directly into your program using the "from modulename import objectname" statement. This makes objectname accessible to your program without needing to prepend it with modulename, and is useful for bringing in names that are often used.
11. 3 The import statement
There are three different forms of the import statement. The most basic,
import modulename
simply searches for a Python module of the given name, parses its contents, and makes it available. The importing code can make use of the contents of the module, but any references by that code to names within the module must still be prepended with the module name. If the named module is not found, an error will be generated. Exactly where Python looks for modules will be discussed shortly.
The second form permits specific names from a module to be explicitly imported into the code:
from modulename import name1, name2, name3, . . .
Each of name1, name2, and so forth, from within modulename are made available to the importing code; code after the import statement can make use of any of name1, name2, name3, . . ., without prepending the module name.
Finally, there's a general form of the from . . . import . . . statement:
from modulename import *
The '* ' stands for all of the names in modulename. This imports almost all names from modulename, and makes them available to the importing code, without the necessity of prepending the module name.
This particular form of importing should be used with some care. If two modules both define a name, and you import both modules using this form of importing, you'll end up with a name clash. It also makes it more difficult for readers of your code to determine where names you are using originate. When using either of the two previous forms of the import statement you give your reader explicit information about where they are from.
However, some modules (such as Tkinter and types, which will be covered later) name their functions such as to make it obvious where they originate, and to make it quite unlikely there will be name clashes. It is standard practice to use this form to import them.
11. 4 The module search path
Exactly where Python looks for modules is defined in a variable called path, which is accessible to the programmer through a module called sys. Do the following:>>> import sys >>> sys. path ==> _list of directories in the search path_
The value shown in place of where I've said ...list of directories in the search path... will depend on the configuration of your system. Regardless of the details, the string indicates a list of directories that are searched by Python (in order), when attempting to execute an import statement. The first module found which satisfies the import request is used. If there is no satisfactory module in the module search path, an ImportError exception is raised.
If you are using IDLE, you can graphically look at the search path and the modules on it using the Path Browser window, which you can start from File menu of the Python Shell window.
The sys. path variable is initialized from the value of the environment (operating system) variable PYTHONPATH, if it exists, or from a default value which is dependent on your installation. In addition, whenever a Python script is run, the sys.path variable for that script will have the directory containing the script inserted as its first element-this provides a convenient way of determining where the executing Python program is located. In an interactive session such as the one just above, the first element of sys.path will be set to the empty string, which Python takes as meaning that it should first look for modules in the current directory.
11. 4.1 Where to place your own modules
In the example that started this chapter, the mymath module was accessible to Python because: (1) when you execute Python interactively, the first element of sys. path is "", telling Python to look for modules in the current directory; and (2) you were executing Python in the directory which contained the mymath.py file. In a production program, neither of these conditions will typically be true. You will not be running Python interactively, and Python code files will not be located in your current directory. In order to ensure that modules coded by you can be used by your programs, you need to do one of the following:- Place your modules into one of the directories that Python normally searches for modules.
- Place all of the modules used by a Python program into the same directory as the program.
- Create a directory (or directories) which will hold your modules, and modify the sys.path variable so that it includes this new directory.
Of these three options, the first is apparently the easiest, and is also an option that should never be chosen because it can cause trouble. For example, what if you place new modules in a standard Python directory, and then you or someone else installs a new version of Python on top of that? Your modules would disappear and your programs would stop working, even if a new installation were done more carefully and you still had the old directory with your modules. You would still have to remember which ones are yours and copy them to their new residence.
Note that it's possible that your version of Python includes local code directories in its default module search path. Such directories are specifically intended for site-specific code, and are not in danger of being overwritten by a new Python install, because they are not part of the Python installation. If your sys.path refers to such directories, put your modules there.
The second option is a good choice for modules that are associated with a particular program. Just keep them with the program.
The third option is the right choice for site-specific modules that will be used in more than one program at that site. You can modify sys.path in various ways. You can assign to it in your code, which is easy, but hard-codes directory locations right into your program code; you can set the PYTHONPATH environment variable, which is relatively easy, but may not apply to all users at your site; or you can add to the default search path using using a .pth file.
See the section on environment variables in the appendix for examples of how to set PYTHONPATH. The directory or directories you set it to are prepended to the sys.path variable. If you use it be careful that you do not define a module with the same name as one of the existing library modules that you are using or is being used for you. Your module will be found before the library module. In some cases this may be what you want, but probably not often.
You can avoid this issue using the .pth method. In this case, the directory or directories you added will be appended to sys.path. The last of these mechanisms is best illustrated by a quick example. On Windows you can place this in the directory pointed to by sys.prefix. Assume your sys.prefix is c:\program files\python, and you place the following file in that directory .
File myModules.pth mymodules c:\My Documents\python\modules
Then the next time a Python interpreter is started, sys. path will have c:\program files\python\mymodules and c:\My Documents\python\modules added to it, if they exist. You can now place your modules in these directories. Note that the mymodules directory still runs the danger of being overwritten with a new installation. The modules directory is safer. You also may have to move or create a mymodules. pth file when you upgrade Python. See the description of the site module in the Python Library Reference if you want more details on using .pth files
11. 5 Private names in modules
We mentioned that you could say from module import * to import almost all names from a module. The exception to this is that names in the module beginning with an underscore cannot be imported in this manner. The primary use of this intentional feature in Python is to permit people to write modules which are intended for importation with from module import *. By leading off all internal names (i. e., names which should not be accessed outside the module) with an underscore, the module writer can ensure that from module import * brings in only those names which the user will want to access.To see this in action let's assume we have a file called modtest. py, containing the following code:
File modtest. Py """ modtest: our test module""" def f( x): return x def _g( x): return x a = 4 _b = 2
Now, start up an interactive session, and try the following:
>>> from modtest import * >>> f(3) ==> 3 >>> _g(3) Traceback (innermost last): File "<stdin>", line 1, in ? NameError: _g >>> a ==> 4 >>> _b Traceback (innermost last): File "< stdin>", line 1, in ? NameError: _b
As you can see, the names f and a were imported, but the names _g and _b remain hidden outside of modtest. Note that this behavior occurs only with from ... import *. We can do the following to access _g or _b:
>>> import modtest >>> modtest._b ==> 2 >>> from modtest import _g >>> _g(5) ==> 5
The convention of leading underscores to indicate private names is used throughout Python, and not just in modules. You'll encounter it in classes and packages, later in the book.
11. 6 Library and third-party modules
It was mentioned at the beginning of this chapter that the standard Python distribution is itself split into modules, to make it more manageable. Once Python has been installed, all of the functionality in these library modules is available to the Python programmer. All that is needed is to import the appropriate modules, functions, classes, and so forth explicitly, before using them.Many of the most common and useful standard modules are discussed throughout this book. However, the standard Python distribution includes far more than what this book describes. At the very least, you should browse through the table of contents of the Python Library Reference.
In IDLE you can also easily browse to and look at those that are written in Python using the Path Browser window. You can also search for example code which uses them with the Find in Files dialog, which can be opened from the Edit menu of the Python Shell window. You can search through your own modules as well in this way.
Available third-party modules, and links to them, are identified on the Python home page. These simply need to be downloaded and placed in a directory in your module search path in order to make them available for import into your programs.
11. 7 Python scoping rules and namespaces
This section on Python's scoping rules and namespaces will become more interesting as your experience as a Python programmer grows. If you are new to Python, you probably don't need to do anything more than quickly read through the text to get the basic ideas. For more details, consult the Python Language Reference.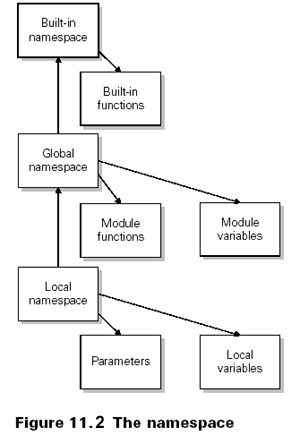
The core concept here is that of a namespace. A namespace in Python is a mapping from identifiers to objects and is usually represented as a dictionary. When a block of code is executed in Python it will have three namespaces: local, global, and built-in (figure 11.2).
When an identifier is encountered during execution, Python first looks in the local namespace for it. If it is not found, the global namespace is looked in next. If it still has not been found the built-in namespace is checked. If it does not exist there, this is considered an error and a NameError exception occurs.
For a module, a command executed in an interactive session or a script running from a file, the global and local namespaces are the same. The creation of any variable or function or importing anything from another module will result in a new entry or binding being made in this namespace.
However, when a function call is made, a local namespace is created and a binding is entered in it for each parameter of the call. A new binding is then entered into this local namespace whenever a variable is created within the function. The global namespace of a function is the global namespace of the containing block of the function (that of the module, script file, or interactive session). It is independent of the dynamic context from which it is called and there is no nested scoping.
In all of the above situations, the built-in namespace will be that of the __builtin__ module. This is the module that contains, among other things, all the built-in functions we've encountered (such as len, min, max, int, float, long, list, tuple, cmp, range, str, and repr) and the other built-in classes in Python such as the exceptions (like NameError).
One thing that sometimes catches new Python programmers is the fact that you can override items in the built-in module. If, for example, you created a list in your program and put it in a variable called list, you would not subsequently be able to use the built-in list function. The entry for your list would be found first. There is no differentiation between names for functions and modules and other objects. The first occurrence of a binding for a given identifier will be used.
Enough talk, time to explore this with some examples. We use two built-in functions, locals and globals. They return dictionaries containing the bindings in the local and global namespaces respectively.
Starting a new interactive session:
>>> locals() {'__ doc__': None, '__ name__': '__ main__', '__ builtins__': <module '__ builtin__'>} >>> globals() {'__ doc__': None, '__ name__': '__ main__', '__ builtins__': <module '__ builtin__'>} >>>
The local and global namespaces for this new interactive session are the same. They have three initial key/ value pairs that are for internal use: (1) an empty documentation string __doc__, (2) the main module name __name__ (which for interactive sessions and scripts run from files is always __main__), and (3) the module used for the built-in namespace __builtins__ (the module __builtin__). Now, if we continue by creating a variable and importing from modules, we will see a number of bindings created:
>>> z = 2 >>> import math >>> from cmath import cos >>> globals() {'math': <module 'math'>, '__doc__': None, 'z': 2, 'cos': <built-in function cos >, '__name__': '__main__', '__builtins__': <module '__builtin__'>} >>> locals() {'math': <module 'math'>, '__doc__': None, 'z': 2, 'cos': <built-in function cos>, '__name__': '__main__', '__builtins__': <module '__builtin__'>} >>> math.ceil(3.4) 4.0
As expected, the local and global namespaces continue to be equivalent. Entries have been added for z as a number, math as a module, and cos from the cmath module as a function.
We can use the del statement to remove these new bindings from the namespace (including the module bindings created with the import statements).
>>> del z, math, cos >>> locals() {'__doc__ ': None, '__name__ ': '__main__ ', '__builtins__ ': <module '__builtin__ '>} >>> math. ceil(3.4) Traceback (innermost last): File "<stdin>", line 1, in ? NameError: math >>> import math >>> math. ceil(3.4) ==> 4
The result was not drastic, as we were able to import the math module and use it again. Using del in this manner can be handy when in the interactive mode. ( Using del and then import again will not pick up changes made to a module on disk. It is not actually removed from memory and then loaded from disk again. The binding is simply taken out of and then put back in your namespace. You still need to use reload if you want to pick up changes made to a file.)
For the trigger happy, yes it is also possible to use del to remove the __doc__, __main__, and __builtins__entries. But resist doing this, as it would not be good for the health of your session!
Now let's take a look at a function created in an interactive session:
>>> def f( x): ... print "global: ", globals() ... print "Entry local: ", locals() ... y = x ... print "Exit local: ", locals() ... >>> z = 2 >>> globals() {'f': <function f at 793d0>, '__doc__': None, 'z': 2, ' __name__': '__main__ ', '__builtins__': <module '__builtin__ '>} >>> f(z) global: {'f': <function f at 793cd0>, '__doc__': None, ' z': 2, '__name__': '__main__', '__builtins__': <module '__builtin__'>} Entry local: {'x': 2} Exit local: {'x': 2, 'y': 2} >>>
If we dissect this apparent mess, we see that, as expected, upon entry the parameter x is the original entry in f's local namespace but y is added later. The global namespace is the same as that of our interactive session, as this is where f was defined. Note that it contains z, which was defined after f.
In a production environment we will normally be calling functions that are defined in modules. Their global namespace will be that of the module they are defined in. Assume we've created the following file:
File scopetest. py """ scopetest: our scope test module""" v = 6 def f( x): """ f: scope test function""" print "global: ", globals(). keys() print "entry local:", locals() y = x w = v print "exit local:", locals()
Note that we will be only printing the keys (identifiers) of the dictionary returned by globals. This will reduce the clutter in the results. It was very necessary in this case due to the fact that in modules as an optimization, the whole __builtin__ dictionary is stored in the value field for the __builtins__ key.
>>> import scopetest >>> z = 2 >>> scopetest. f( z) global: ['v', '__doc__', 'f', '__file__', '__name__ ', '__builtins__'] entry local: {'x': 2} exit local: {'w': 6, 'x': 2, 'y': 2}
The global namespace is now that of the scopetest module and includes the function f and integer v (but not z from our interactive session). Thus, when creating a module you have complete control of the namespaces of its functions.
We've now covered local and global namespaces. Next, let's move on to the built-in namespace. We'll introduce another built-in function, dir, which, given a module, returns a list of the names defined in it.
>>> dir(__builtins__) ==> ['ArithmeticError', 'AssertionError', 'AttributeError', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'FloatingPointError', 'IOError', 'ImportError', 'IndexError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'NameError', 'None', 'NotImplementedError', 'OSError', 'OverflowError', 'RuntimeError', 'StandardError', 'SyntaxError', 'SystemError', 'SystemExit', 'TypeError', 'ValueError', 'ZeroDivisionError', '_', '__debug__', '__doc__', '__import__', '__name__', 'abs', 'apply', 'callable', 'chr', 'cmp', 'coerce', 'compile', 'complex', 'delattr', 'dir', 'divmod', 'eval', 'execfile', 'exit', 'filter', 'float', 'getattr', 'globals', 'hasattr', 'hash', 'hex', 'id', 'input', 'int', 'intern', 'isinstance', 'issubclass', 'len', 'list', 'locals', 'long', 'map', 'max', 'min', 'oct', 'open', 'ord', 'pow', 'quit', 'range', 'raw_ input', 'reduce', 'reload', 'repr', 'round', 'setattr', 'slice', 'str', 'tuple', 'type', 'vars', 'xrange']
There are a lot of entries here. Those ending in Error and System Exit are the names of the exceptions built-in to Python. These will be discussed in "Exceptions" (chapter 14).
The last group (from abs to xrange), are built-in functions of Python. We have already seen many of these in this book and will see more. However, they won't all be covered here. When interested, you can find details on the rest in the Python Library Reference. You can also at any time easily obtain the documentation string for any of them:
>>> print max.__doc__ max(sequence) -> value max(a, b, c, ...) -> value With a single sequence argument, return its largest item. With two or more arguments, return the largest argument. >>>
As mentioned earlier, it is not unheard of for a new Python programmer to inadvertently override a built-in function.
>>> list("Peyto Lake") ['P', 'e', 'y', 't', 'o', ' ', 'L', 'a', 'k', 'e'] >>> list = [1,3,5,7] >>> list("Peyto Lake") Traceback (innermost last): File "<stdin>", line 1, in ? TypeError: call of non-function (type list)
The Python interpreter will not look beyond our new binding for list as a list, even though we are using function syntax.
The same thing will of course happen if we try to use the same identifier twice in a single namespace. The previous value will be overwritten, regardless of its type:
>>> import string >>> string = "Mount Rundle" >>> string.split("Bow Lake") Traceback (innermost last): File "<stdin>", line 1, in ? AttributeError: 'string' object has no attribute 'split'
Once aware of this, it isn't a significant issue. Reusing identifiers, even for different types of objects, wouldn't make for the most readable code anyway. If we do inadvertently make one of these mistakes when in interactive mode, it's easy to recover. We can use del to remove our binding, to regain access to an overridden built-in, or import our module again, to regain access.
>>> del list >>> list("Peyto Lake") ==> ['P', 'e', 'y', 't', 'o', ' ', 'L', 'a', 'k', 'e'] >>> import string >>> string.split("Bow Lake") ==> ['Bow', 'Lake']
The locals and globals functions can be quite useful as simple debugging tools. The dir function doesn't give the current settings but if called without parameters, it returns a sorted list of the identifiers in the local namespace. This will help catch the mistyped variable error that compilers may usually catch for you in languages that require declarations:
>>> x1 = 6 >>> xl = x1 -2 >>> x1 ==> 6 >>> dir() ==> ['__builtins__', '__doc__', '__name__', 'x1', 'xl']
The debugger that is bundled with IDLE has settings where you can view the local and global variable settings as you step through your code, and what it displays is the output of the locals and globals functions.
Daryl Harms holds a Ph.D. in computer science. He has been working on the design and the development (or the management of the development) of small and large software systems since the mid-1980's. He is currently a software development consultant working out of Calgary, Alberta and can be reached at ddharms@yahoo.com
Kenneth McDonald is a longtime programmer/analyst and advocate for free software. He holds the B.Sc. and M.Sc. in computer science and has been, at various times, a Unix system administrator, independent software developer, and investor. His most recent position was with the Washington University School of Medicine, where he worked as part of the Human Genome Project as a programmer/analyst.